本文目录导读:
在人工智能领域,每一次技术的突破都可能引领一场新的革命,斯坦福大学的吴恩达团队再次传来振奋人心的消息,他们最新发表的关于多模态多样本上下文学习(Many-shot In-Context Learning,ManyICL)的研究成果,为AI模型快速适应新任务和新领域提供了新的可能,这项研究不仅揭示了利用大量演示示例可以快速适应新任务和新领域,而且无需传统的微调过程,这无疑为AI技术的发展开辟了新的路径。
研究背景与动机
在近年来,多模态基础模型(Multimodal Foundation Model)的研究日益受到关注,这类模型能够处理来自不同模态的信息,如文本、图像、音频等,更接近于人类处理信息的方式,传统的多模态模型在适应新任务时,往往需要经过繁琐的微调过程,这不仅耗时耗力,还可能限制模型的泛化能力,如何使多模态模型能够更快速、更灵活地适应新任务,成为了AI领域亟待解决的问题。
在此背景下,吴恩达团队提出了多模态多样本上下文学习的概念,他们发现,通过增加上下文中的示例数量,可以显著提升模型的性能,而无需进行传统的微调,这一发现为AI模型的快速适应提供了新的思路。
研究方法与过程
为了验证这一想法,吴恩达团队选择了三种先进的多模态基础模型:GPT-4o、GPT4 (V)-Turbo和Gemini 1.5 Pro,这些模型在文本和图像处理方面均表现出色,是研究多模态学习的理想选择。
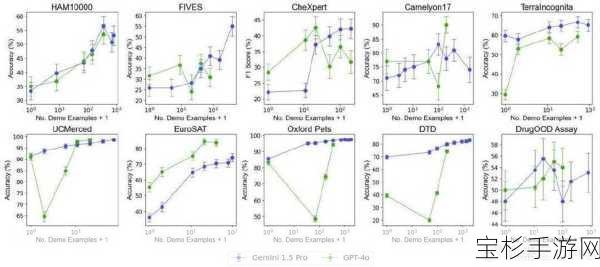
研究团队在10个跨越不同领域和任务的数据集上进行了广泛的实验,这些数据集涵盖了自然影像、医学影像、遥感影像和分子影像等多个领域,以及多分类、多标签分类和细粒度分类等多种任务,通过逐步增加上下文中提供的示例数量,研究团队测试了模型在不同示例数量下的性能表现。
考虑到多样本学习的高成本和高延迟,研究团队还探索了批量处理查询的影响,批量查询指的是在单次API调用中处理多个查询,这有助于降低每个示例的延迟和推理成本。
研究成果与亮点
研究结果表明,包含近2000个示例的多样本上下文学习在所有数据集上均优于少样本学习,随着示例数量的增加,Gemini 1.5 Pro模型的性能呈现出持续的对数线性提升,而GPT-4o的表现虽然较不稳定,但也呈现出一定的上升趋势。
在数据效率方面,Gemini 1.5 Pro在绝大部分数据集上显示出比GPT-4o更高的上下文学习数据效率,这意味着Gemini 1.5 Pro能够更有效地从示例中学习,从而更快地适应新任务。
研究团队还发现,在选择最优示例集大小下的零样本和多样本情境中,将多个查询合并为一次请求(即批量查询)并不会降低性能,相反,在某些数据集上,批量查询甚至可以提高性能,这主要归因于领域校准(domain calibration)、类别校准(class calibration)以及自我学习(self-ICL)等机制的作用。
值得注意的是,多样本上下文学习虽然在推理时需要处理更长的输入上下文,但通过批量查询可以显著降低每个示例的延迟和推理成本,在HAM10000数据集中,使用Gemini 1.5 Pro模型进行350个示例的批量查询,延迟从17.3秒降至0.54秒,成本从每个示例0.842美元降至0.0877美元,这一发现为多样本上下文学习在实际应用中的推广提供了有力支持。
研究意义与未来展望
吴恩达团队的这项研究为多模态基础模型的应用开辟了新的路径,通过多样本上下文学习,AI模型能够更快速、更灵活地适应新任务和新领域,而无需传统的微调过程,这不仅降低了模型部署的成本和时间,还提高了模型的泛化能力和实用性。
随着技术的不断发展,多模态多样本上下文学习有望在更多领域得到应用,在医疗影像分析领域,医生可以利用这一技术快速识别和分析患者的医学影像资料;在自动驾驶领域,车辆可以通过学习大量交通场景数据来提高驾驶安全性和准确性;在智能客服领域,机器人可以通过学习用户对话数据来提供更智能、更个性化的服务。
我们也期待吴恩达团队能够继续深入研究多模态学习领域的其他问题,如如何进一步提高模型的性能、如何降低模型的复杂度和计算成本等,相信在他们的努力下,AI技术将会迎来更加广阔的发展前景。
吴恩达团队的这项研究为多模态基础模型的应用带来了新的突破和机遇,通过多样本上下文学习,我们可以期待AI模型在未来能够更加智能、更加高效地服务于人类社会。